MySQL高可用、高性能、高可擴展性(三高)詳解之二 InnoDB數(shù)據(jù)表存儲機制與數(shù)據(jù)處理服務(wù)
2.4 InnoDB數(shù)據(jù)表是如何存儲的:數(shù)據(jù)處理和存儲服務(wù)
在MySQL的“三高”(高可用、高性能、高可擴展性)架構(gòu)中,存儲引擎是核心基石,而InnoDB作為其默認和最重要的存儲引擎,其數(shù)據(jù)存儲機制直接決定了數(shù)據(jù)庫的性能、可靠性與擴展能力。本節(jié)將深入解析InnoDB數(shù)據(jù)表的物理與邏輯存儲結(jié)構(gòu),并闡述其如何提供高效的數(shù)據(jù)處理與存儲服務(wù)。
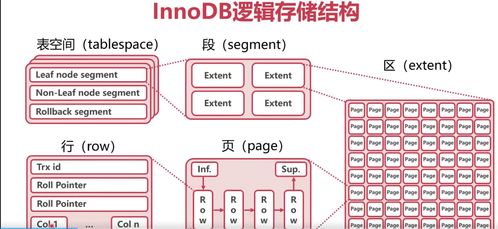
一、邏輯存儲結(jié)構(gòu):表空間與段、區(qū)、頁
InnoDB的存儲結(jié)構(gòu)是一個層次化的體系,從邏輯上分為表空間、段、區(qū)和頁。
- 表空間(Tablespace):
- 系統(tǒng)表空間(ibdata1):在MySQL 5.7及更早版本中,默認存放所有InnoDB表的元數(shù)據(jù)(數(shù)據(jù)字典)、UNDO日志、Change Buffer等。
- 獨立表空間(file-per-table tablespace):從MySQL 5.6開始默認啟用,每個InnoDB表對應(yīng)一個獨立的
.ibd文件。這極大地提升了管理的靈活性,支持單表備份、恢復(fù)和遷移,是“高可擴展性”和“高可用”運維的基礎(chǔ)。
- 通用表空間(General Tablespace):允許將多個表集中存儲在一個表空間中,便于管理和空間復(fù)用。
- 臨時表空間、UNDO表空間:分別用于存儲臨時表和UNDO日志,支持獨立配置,有助于性能優(yōu)化。
- 段(Segment):表空間由多個段組成,常見的段有數(shù)據(jù)段、索引段、回滾段等。一個索引會占用兩個段:一個存放B+樹的非葉子節(jié)點(索引段),一個存放葉子節(jié)點(數(shù)據(jù)段)。
- 區(qū)(Extent):段由多個區(qū)構(gòu)成,每個區(qū)大小為1MB(在默認頁大小為16KB時,包含64個連續(xù)頁)。區(qū)是InnoDB進行空間分配和管理的單位,連續(xù)分配有助于提高I/O效率(順序I/O),這是“高性能”的關(guān)鍵設(shè)計之一。
- 頁(Page):區(qū)由頁組成,頁是InnoDB磁盤管理的最小單位,默認大小為16KB。頁也是內(nèi)存與磁盤交互的基本單元。常見的頁類型包括:
- 數(shù)據(jù)頁(INDEX):存儲實際的表行數(shù)據(jù)(在聚簇索引的葉子節(jié)點)和索引鍵值。
- UNDO頁:存儲舊版本數(shù)據(jù),用于實現(xiàn)MVCC和事務(wù)回滾。
- 系統(tǒng)頁、事務(wù)數(shù)據(jù)頁、插入緩沖位圖頁等。
二、物理存儲結(jié)構(gòu):.ibd文件剖析
當啟用獨立表空間時,每個表對應(yīng)一個 .ibd 文件。其內(nèi)部結(jié)構(gòu)可以概括為:
- 文件頭(FIL Header):包含文件ID、表空間ID、校驗和等元信息。
- 區(qū)(Extent)鏈表管理:文件內(nèi)部維護著空閑區(qū)、已使用的區(qū)等鏈表,用于高效的空間分配與回收。
- 索引(B+樹)的物理組織:
- InnoDB表的數(shù)據(jù)和主鍵索引是“聚簇”的,即表數(shù)據(jù)本身按照主鍵順序組織成一棵B+樹。葉子節(jié)點包含了完整的行數(shù)據(jù)。
- 二級索引(非主鍵索引)同樣是一棵B+樹,但其葉子節(jié)點存儲的不是完整行數(shù)據(jù),而是該索引的鍵值列和對應(yīng)的主鍵值。查詢時若需非索引列,需要通過主鍵值回表查詢聚簇索引,這一設(shè)計在空間和性能上做了權(quán)衡。
- 每個索引的根頁位置固定在表空間中。B+樹的多層結(jié)構(gòu)使得查找效率極高(通常只需3-4次I/O),支撐了數(shù)據(jù)庫的“高性能”查詢。
- 行格式(Row Format):行數(shù)據(jù)在頁內(nèi)的存儲格式,如
COMPACT、DYNAMIC(MySQL 5.7默認)、COMPRESSED等。DYNAMIC格式對可變長列(如VARCHAR,TEXT,BLOB)處理更優(yōu),將可能溢出的列存儲在溢出頁,減少數(shù)據(jù)頁分裂,提升空間利用率和I/O效率。
三、數(shù)據(jù)處理與存儲服務(wù)
InnoDB不僅僅是一個靜態(tài)的存儲容器,它通過一系列核心服務(wù),將底層存儲轉(zhuǎn)化為安全、高效、一致的數(shù)據(jù)處理能力:
- 事務(wù)處理服務(wù):
- REDO日志(重做日志,ib_logfile):采用Write-Ahead Logging(WAL)機制。所有數(shù)據(jù)變更先寫入順序的REDO日志文件,再異步刷回數(shù)據(jù)文件。這確保了事務(wù)的持久性(Durability),并且在崩潰恢復(fù)時能快速重演操作,是實現(xiàn)“高可用”中崩潰恢復(fù)的核心。
- UNDO日志(回滾日志):存儲在獨立的UNDO表空間或系統(tǒng)表空間中。記錄了數(shù)據(jù)修改前的舊版本,用于事務(wù)回滾和實現(xiàn)多版本并發(fā)控制(MVCC)。MVCC使得讀操作不會阻塞寫操作,極大提升了并發(fā)性能,是“高性能”并發(fā)讀寫的關(guān)鍵。
- 緩存與緩沖服務(wù):
- 緩沖池(Buffer Pool):這是InnoDB最重要的內(nèi)存區(qū)域。它將頻繁訪問的數(shù)據(jù)頁和索引頁緩存在內(nèi)存中,減少直接磁盤I/O。其大小配置(
innodb<em>buffer</em>pool_size)對性能有決定性影響。它內(nèi)部采用LRU算法管理,并細分為年輕代和老年代,防止全表掃描等操作污染熱點緩存。
- Change Buffer(變更緩沖):專門緩存對二級索引的插入、更新、刪除操作。當相關(guān)索引頁不在緩沖池時,操作被緩存在Change Buffer,待未來該頁被讀取時再合并,從而減少隨機I/O,提升寫性能。這對寫多讀少的場景尤其有益。
- 自適應(yīng)哈希索引(Adaptive Hash Index):InnoDB會自動監(jiān)控表索引的查找模式,如果發(fā)現(xiàn)某索引值被頻繁用等值查詢,它會在內(nèi)存中為其建立一個哈希索引,以加速查詢。這是一個完全自動化的優(yōu)化過程。
- 鎖與并發(fā)控制服務(wù):
- 提供行級鎖,最小化鎖沖突。
- 通過
MVCC和Next-Key Lock(臨鍵鎖)機制,在保證事務(wù)隔離級別(如默認的REPEATABLE READ)的平衡并發(fā)性能和數(shù)據(jù)一致性。
四、與“三高”目標的關(guān)聯(lián)
- 高性能:B+樹索引結(jié)構(gòu)、緩沖池、Change Buffer、自適應(yīng)哈希索引、順序?qū)懙腞EDO日志等,共同保障了極快的讀寫速度和高并發(fā)處理能力。
- 高可用:WAL機制(REDO日志)確保了崩潰恢復(fù)能力;獨立表空間避免了單文件損壞導(dǎo)致全庫不可用;熱備份工具(如
Percona XtraBackup)直接利用InnoDB的物理結(jié)構(gòu)進行高效備份。這些是構(gòu)建主從復(fù)制、高可用集群(如MHA、Orchestrator)的基礎(chǔ)。 - 高可擴展:獨立表空間使得表可以方便地在不同存儲介質(zhì)或服務(wù)器間遷移。在線DDL(如
ALGORITHM=INPLACE)支持在業(yè)務(wù)不中斷的情況下修改表結(jié)構(gòu)。這些特性為數(shù)據(jù)的水平與垂直拆分提供了便利。
****:InnoDB通過其精巧的分層存儲結(jié)構(gòu)(表空間-段-區(qū)-頁)將數(shù)據(jù)有序組織,再結(jié)合其強大的內(nèi)存緩沖機制(緩沖池、Change Buffer)、可靠的日志系統(tǒng)(REDO/UNDO)以及行級鎖與MVCC,構(gòu)建了一套完整、高效、穩(wěn)定的數(shù)據(jù)存儲與處理服務(wù)引擎。深入理解其存儲原理,是進行MySQL性能調(diào)優(yōu)、設(shè)計高可用架構(gòu)和實現(xiàn)業(yè)務(wù)可擴展性的必經(jīng)之路。
如若轉(zhuǎn)載,請注明出處:http://m.pumachine.cn/product/52.html
更新時間:2026-05-23 06:24:34